Model composition¶
Model composition lets you combine multiple models to build sophisticated AI applications such as RAG and AI agents. BentoML provides simple Service APIs for creating workflows where models need to work together - either in sequence (one after another) or in parallel (at the same time).
You might want to use model composition in BentoML when you need to:
Process different types of data together (for example, images and text) with different models
Improve accuracy and performance by combining results from multiple models
Run different models on specialized hardware (for example, GPUs and CPUs)
Orchestrate sequential steps like preprocessing, inference, and postprocessing with specialized models or services
See also
For more information, see the blog post A Guide to Model Composition.
Examples¶
Model composition in BentoML can involve single or multiple Services, depending on your application.
For each Service, you can use resources in the @bentoml.service decorator to configure the required resources for deployment, such as GPUs. Note that this field only takes effect on BentoCloud.
Run multiple models in one Service¶
You can run multiple models on the same hardware device and expose separate or combined APIs for them.
import bentoml
from bentoml.models import HuggingFaceModel
from transformers import pipeline
from typing import List
# Run two models in the same Service on the same hardware device
@bentoml.service(
resources={"gpu": 1, "memory": "4GiB"},
traffic={"timeout": 20},
)
class MultiModelService:
# Retrieve model references from HF by specifying its HF ID
model_a_path = HuggingFaceModel("FacebookAI/roberta-large-mnli")
model_b_path = HuggingFaceModel("distilbert/distilbert-base-uncased")
def __init__(self) -> None:
# Initialize pipelines for each model
self.pipeline_a = pipeline(task="zero-shot-classification", model=self.model_a_path, hypothesis_template="This text is about {}")
self.pipeline_b = pipeline(task="sentiment-analysis", model=self.model_b_path)
# Define an API for data processing with model A
@bentoml.api
def process_a(self, input_data: str, labels: List[str] = ["positive", "negative", "neutral"]) -> dict:
return self.pipeline_a(input_data, labels)
# Define an API for data processing with model B
@bentoml.api
def process_b(self, input_data: str) -> dict:
return self.pipeline_b(input_data)[0]
# Define an API endpoint that combines the processing of both models
@bentoml.api
def combined_process(self, input_data: str, labels: List[str] = ["positive", "negative", "neutral"]) -> dict:
classification = self.pipeline_a(input_data, labels)
sentiment = self.pipeline_b(input_data)[0]
return {
"classification": classification,
"sentiment": sentiment
}
Note
The HuggingFaceModel function returns the downloaded model path as a string. You must pass in the model ID as shown on Hugging Face (for example, HuggingFaceModel("FacebookAI/roberta-large-mnli")). See Load and manage models for details.
Run and scale multiple models independently in separate Services¶
When your models need independent scaling or different hardware, split them into separate Services.
Sequential¶
You can let models work in a sequence, where the output of one model becomes the input for another. This is useful for creating pipelines where data needs to be preprocessed before being used for predictions.
import bentoml
from bentoml.models import HuggingFaceModel
from transformers import pipeline
from typing import Dict, Any
@bentoml.service(resources={"cpu": "2", "memory": "2Gi"})
class PreprocessingService:
model_a_path = HuggingFaceModel("distilbert/distilbert-base-uncased")
def __init__(self) -> None:
# Initialize pipeline for model A
self.pipeline_a = pipeline(task="text-classification", model=self.model_a_path)
@bentoml.api
def preprocess(self, input_data: str) -> Dict[str, Any]:
# Dummy preprocessing steps
return self.pipeline_a(input_data)[0]
@bentoml.service(resources={"gpu": 1, "memory": "4Gi"})
class InferenceService:
model_b_path = HuggingFaceModel("distilbert/distilroberta-base")
preprocessing_service = bentoml.depends(PreprocessingService)
def __init__(self) -> None:
# Initialize pipeline for model B
self.pipeline_b = pipeline(task="text-classification", model=self.model_b_path)
@bentoml.api
async def predict(self, input_data: str) -> Dict[str, Any]:
# Dummy inference on preprocessed data
# Implement your custom logic here
preprocessed_data = await self.preprocessing_service.to_async.preprocess(input_data)
final_result = self.pipeline_b(input_data)[0]
return {
"preprocessing_result": preprocessed_data,
"final_result": final_result
}
You use bentoml.depends to access one Service from another. It accepts the dependent Service class as an argument and allows you to call its available function. See Run distributed Services for details.
You use the .to_async property of a Service to convert a synchronous method to asynchronous. Note that directly calling a synchronous blocking function within an asynchronous context is not recommended, since it can block the event loop.
Concurrent¶
You can run multiple independent models at the same time and then combine their results. This is useful for ensemble models where you want to aggregate predictions from different models to improve accuracy.
import asyncio
import bentoml
from bentoml.models import HuggingFaceModel
from transformers import pipeline
from typing import Dict, Any, List
@bentoml.service(resources={"gpu": 1, "memory": "4Gi"})
class ModelAService:
model_a_path = HuggingFaceModel("FacebookAI/roberta-large-mnli")
def __init__(self) -> None:
# Initialize pipeline for model A
self.pipeline_a = pipeline(task="zero-shot-classification", model=self.model_a_path, hypothesis_template="This text is about {}")
@bentoml.api
def predict(self, input_data: str, labels: List[str] = ["positive", "negative", "neutral"]) -> Dict[str, Any]:
# Dummy preprocessing steps
return self.pipeline_a(input_data, labels)
@bentoml.service(resources={"gpu": 1, "memory": "4Gi"})
class ModelBService:
model_b_path = HuggingFaceModel("distilbert/distilbert-base-uncased")
def __init__(self) -> None:
# Initialize pipeline for model B
self.pipeline_b = pipeline(task="sentiment-analysis", model=self.model_b_path)
@bentoml.api
def predict(self, input_data: str) -> Dict[str, Any]:
# Dummy preprocessing steps
return self.pipeline_b(input_data)[0]
@bentoml.service(resources={"cpu": "4", "memory": "8Gi"})
class EnsembleService:
service_a = bentoml.depends(ModelAService)
service_b = bentoml.depends(ModelBService)
@bentoml.api
async def ensemble_predict(self, input_data: str, labels: List[str] = ["positive", "negative", "neutral"]) -> Dict[str, Any]:
result_a, result_b = await asyncio.gather(
self.service_a.to_async.predict(input_data, labels),
self.service_b.to_async.predict(input_data)
)
# Dummy aggregation
return {
"zero_shot_classification": result_a,
"sentiment_analysis": result_b
}
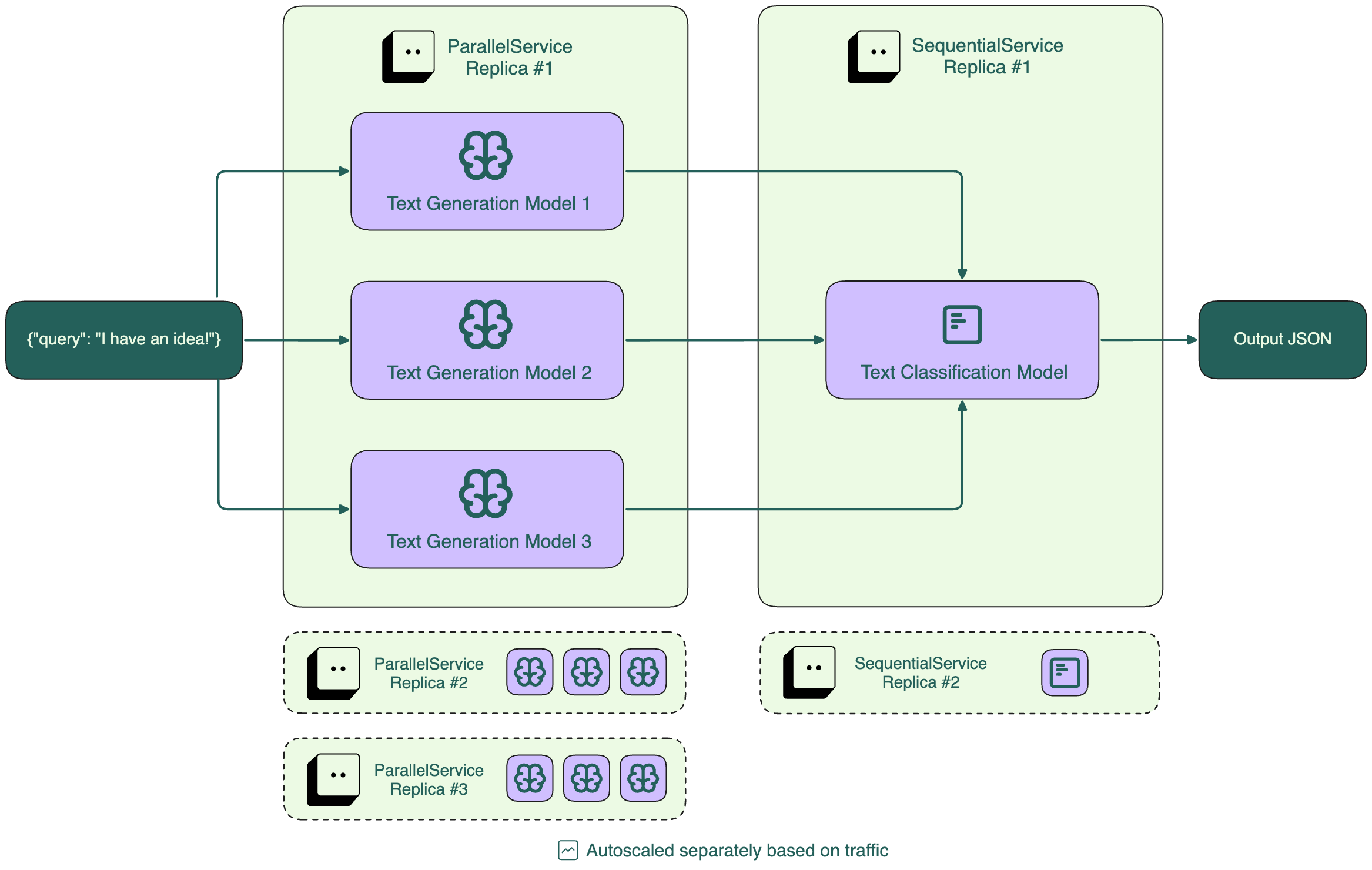
Inference graph¶
You can create more complex workflows that combine both parallel and sequential processing.
import asyncio
import typing as t
import transformers
import bentoml
MAX_LENGTH = 128
NUM_RETURN_SEQUENCE = 1
@bentoml.service(
resources={"gpu": 1, "memory": "4Gi"}
)
class GPT2:
model_path = bentoml.models.HuggingFaceModel("openai-community/gpt2")
def __init__(self):
self.generation_pipeline_1 = transformers.pipeline(
task="text-generation",
model=self.model_path,
)
@bentoml.api
def generate(self, sentence: str) -> t.List[t.Any]:
return self.generation_pipeline_1(sentence)
@bentoml.service(
resources={"gpu": 1, "memory": "4Gi"}
)
class DistilGPT2:
model_path = bentoml.models.HuggingFaceModel("distilbert/distilgpt2")
def __init__(self):
self.generation_pipeline_2 = transformers.pipeline(
task="text-generation",
model=self.model_path,
)
@bentoml.api
def generate(self, sentence: str) -> t.List[t.Any]:
return self.generation_pipeline_2(sentence)
@bentoml.service(
resources={"cpu": "2", "memory": "2Gi"}
)
class BertBaseUncased:
model_path = bentoml.models.HuggingFaceModel("google-bert/bert-base-uncased")
def __init__(self):
self.classification_pipeline = transformers.pipeline(
task="text-classification",
model=self.model_path,
tokenizer=self.model_path,
)
@bentoml.api
def classify_generated_texts(self, sentence: str) -> float | str:
score = self.classification_pipeline(sentence)[0]["score"] # type: ignore
return score
@bentoml.service(
resources={"cpu": "4", "memory": "8Gi"}
)
class InferenceGraph:
gpt2_generator = bentoml.depends(GPT2)
distilgpt2_generator = bentoml.depends(DistilGPT2)
bert_classifier = bentoml.depends(BertBaseUncased)
@bentoml.api
async def generate_score(
self, original_sentence: str = "I have an idea!"
) -> t.List[t.Dict[str, t.Any]]:
generated_sentences = [ # type: ignore
result[0]["generated_text"]
for result in await asyncio.gather( # type: ignore
self.gpt2_generator.to_async.generate( # type: ignore
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
self.distilgpt2_generator.to_async.generate( # type: ignore
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
)
]
results = []
for sentence in generated_sentences: # type: ignore
score = await self.bert_classifier.to_async.classify_generated_texts(
sentence
) # type: ignore
results.append(
{
"generated": sentence,
"score": score,
}
)
return results
This example creates a workflow that:
Takes a text prompt as input
Generates new text using GPT2 and DistilGPT2 in parallel
Scores each generated text response using BERT sequentially
Returns both the generated text and their scores
Note
In some cases, you may want to stream output directly from one LLM to another LLM as input to build a compound LLM system. This is not yet supported in BentoML, but it is on its roadmap. If you are interested in this topic, you are welcome to join our discussion in the community forum or raise an issue in GitHub.