Inference Graph#
Many ML problems require an ensemble of models to work together to solve. BentoML architecture can support any model inference graph natively in its Service APIs definition. Users can define parallel and sequential inference graphs with any control flows by writing simple Python code. In this guide, we will build a text generation and classification service using model inference graph. The project source code can be found in the BentoML inference graph example.

As illustrated in the diagram above, the service performs the following tasks.
Accepts a text input.
Passes the input to three text generation models in parallel and receives a list of three generated texts.
Passes the list of generated texts to a text classification model iteratively and receives a list of three classification results.
Returns the list of generated texts and classification results in a JSON output.
[
{
"generated": "I have an idea! Please share with, like and subscribe and leave a comment below!\n\nIf you like this post, please consider becoming a patron of Reddit or becoming a patron of the author.",
"score": 0.5149753093719482
},
{
"generated": "I have an idea! One that won't break your heart but will leave you gasping in awe. A book about the history of magic. And because what's better than magic? Some. It's a celebration of our ancient, universal gift of awe.\"\n\nThe result was the \"Vox Populi: A Memoir of the Ancient World\" by E.V. Okello (Ace Books), published in 1999.\n\nIn the past 20 years, Okello, professor of history at Ohio State University and author of such titles as \"The American Imagination\" and \"Walking With Elephants",
"score": 0.502700924873352
},
{
"generated": "I have an idea! I've been wondering what the name of this thing is. What's the point?\" - The Simpsons\n\n\n\"It's bigger, bigger than she needs!\" - SpongeBob SquarePants\n\n\n\"That's a funny thing. It's like my brain is the most gigantic living thing. I just like thinking big.\" - Simpsons\n\n\n\"Ooookay! Here comes Barty-Icarus himself! (pause)\" - A Christmas Tale\n\n\nBackground information Edit\n\nFormal name: Homer's Brain.\n\nHomer's Brain. Special name: Brain.\n\nAppearances Edit",
"score": 0.536346971988678
}
]
Declare Runners#
Create Runners for the three text generation models and the one text classification model using the to_runner function.
gpt2_generator = bentoml.transformers.get("gpt2-generation:latest").to_runner()
distilgpt2_generator = bentoml.transformers.get("distilgpt2-generation:latest").to_runner()
distilbegpt2_medium_generator = bentoml.transformers.get("gpt2-medium-generation:latest").to_runner()
bert_base_uncased_classifier = bentoml.transformers.get("bert-base-uncased-classification:latest").to_runner()
Create Service#
Create a Service named inference_graph and specify the runners created earlier in the runners argument.
svc = bentoml.Service(
"inference_graph",
runners=[
gpt2_generator,
distilgpt2_generator,
distilbegpt2_medium_generator,
bert_base_uncased_classifier,
],
)
Define API#
First, define an async API named classify_generated_texts that accepts a Text
input and returns JSON output. Second, pass the input simultaneously to all three text generation
runners through asyncio.gather and receive a list of three generated texts. Using asyncio.gather and Runner’s async_run allows the inferences to happen
in parallel. Third, pass the list of generated texts to the text classification runner iteratively using a loop to get the classification score of each generated text.
Finally, return the list of generated texts and classification results in a dictionary.
Tip
Using asynchronous Service and Runner APIs achives better performance and throughput for IO-intensive workloads. See Sync vs Async APIs for more details.
@svc.api(input=Text(), output=JSON())
async def classify_generated_texts(original_sentence: str) -> dict:
generated_sentences = [
result[0]["generated_text"]
for result in await asyncio.gather(
gpt2_generator.async_run(
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
distilgpt2_generator.async_run(
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
distilbegpt2_medium_generator.async_run(
original_sentence,
max_length=MAX_LENGTH,
num_return_sequences=NUM_RETURN_SEQUENCE,
),
)
]
results = []
for sentence in generated_sentences:
score = (await bert_base_uncased_classifier.async_run(sentence))[0]["score"]
results.append(
{
"generated": sentence,
"score": score,
}
)
return results
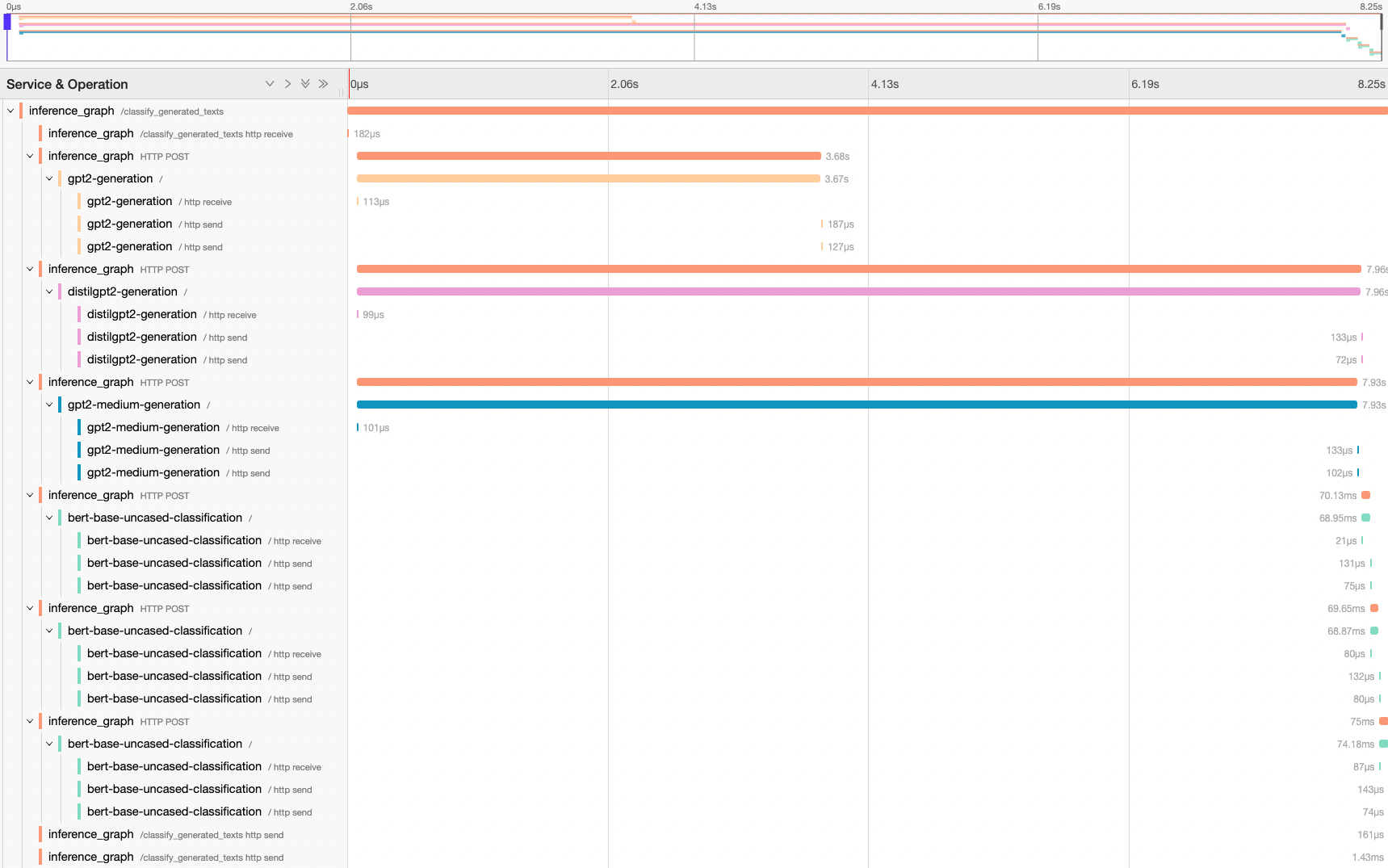
Inference Graph Trace#
The following tracing waterfall graphs demonstrates the execution flow of the inference graph. Note that the three calls to the text generation runners happen in parallel without blocking each other and the calls to the text classification runner happen sequentially.