What is BentoML?#
BentoML is a unified AI application framework for building reliable, scalable, and cost-efficient AI applications. It provides an end-to-end solution for streamlining the deployment process, incorporating everything you need for model serving, application packaging, and production deployment.
Who is BentoML for?#
BentoML is designed for teams working to bring machine learning (ML) models into production in a reliable, scalable, and cost-efficient way. In particular, AI application developers can leverage BentoML to easily integrate state-of-the-art pre-trained models into their applications. By seamlessly bridging the gap between model creation and production deployment, BentoML promotes collaboration between developers and in-house data science teams.
Why BentoML?#
BentoML’s comprehensive toolkit for AI application development provides a unified distribution format, which features a simplified AI architecture and supports deployment anywhere.
Streamline distribution with a unified format#
ML projects often involve different roles and complex collaboration. BentoML simplifies this process through a unified distribution format - a file archive known as a Bento. With BentoML’s open standard and SDK for AI applications, you can package all the necessary components into a Bento.
You can manage all the Bentos in the local Bento Store and keep iterating them as your application evolves. BentoML auto-generates API servers within Bentos, offering support for REST APIs, gRPC, and long-running inference jobs. Each Bento includes an auto-generated Dockerfile, enabling easy containerization for deployment.
Build applications with any AI models#
BentoML provides the flexibility and ease to build any AI applications with any tools your team prefers. Whether you want to import models from any model hub or bring your own models built with frameworks such as PyTorch, TensorFlow, Keras, Scikit-Learn, XGBoost, and many more, you can use BentoML’s local Model Store to manage them and build applications on top of them.
BentoML offers native support for Large Language Model (LLM) inference, Generative AI, embedding creation, and multi-modal AI applications. Additionally, it integrates smoothly with popular tools like MLFlow, LangChain, Kubeflow, Triton, Spark, Ray, and many more to complete your production AI stack.
Inference optimization for AI applications#
BentoML’s proven open-source architecture ensures high performance for your AI applications through efficient resource utilization and latency reduction techniques. It supports model inference parallelization and adaptive batching. With built-in optimization for specific model architectures (like OpenLLM for LLMs) and support for high-performance runtimes like ONNX-runtime and TorchScript, BentoML delivers faster response time and higher throughput, offering scalable and cost-efficient backbone infrastructure for any AI applications.
Simplify modern AI application architectures#
BentoML is designed with a Python-first approach, ensuring the effortless scalability of complex AI workloads. It simplifies the architecture of modern AI applications by allowing you to compose multiple models to run either concurrently or sequentially, across multiple GPUs or on a Kubernetes cluster. This flexibility extends to running and debugging your BentoML applications locally, whether you are using Mac, Windows, or Linux.
Build once. Deploy anywhere#
BentoML standardizes the saved model format, Service API definition and the Bento build process, which opens up many different deployment options for ML teams. You can deploy your models virtually anywhere. Deployment options include:
One-click deployment to BentoCloud, a fully-managed platform specifically designed for hosting and operating AI applications.
Containerize Bentos and deploy the images to any environment where Docker runs, such as Kubernetes.
How does BentoML work?#
In a typical ML workflow, you may need to prepare the data for your model, train and evaluate the model, serve the model in production, monitor its performance, and retrain the model for better inferences and predictions. BentoML features a streamlined path for transforming an ML model into a production-ready model serving endpoint. See the following diagram to understand the role of BentoML in the ML workflow:
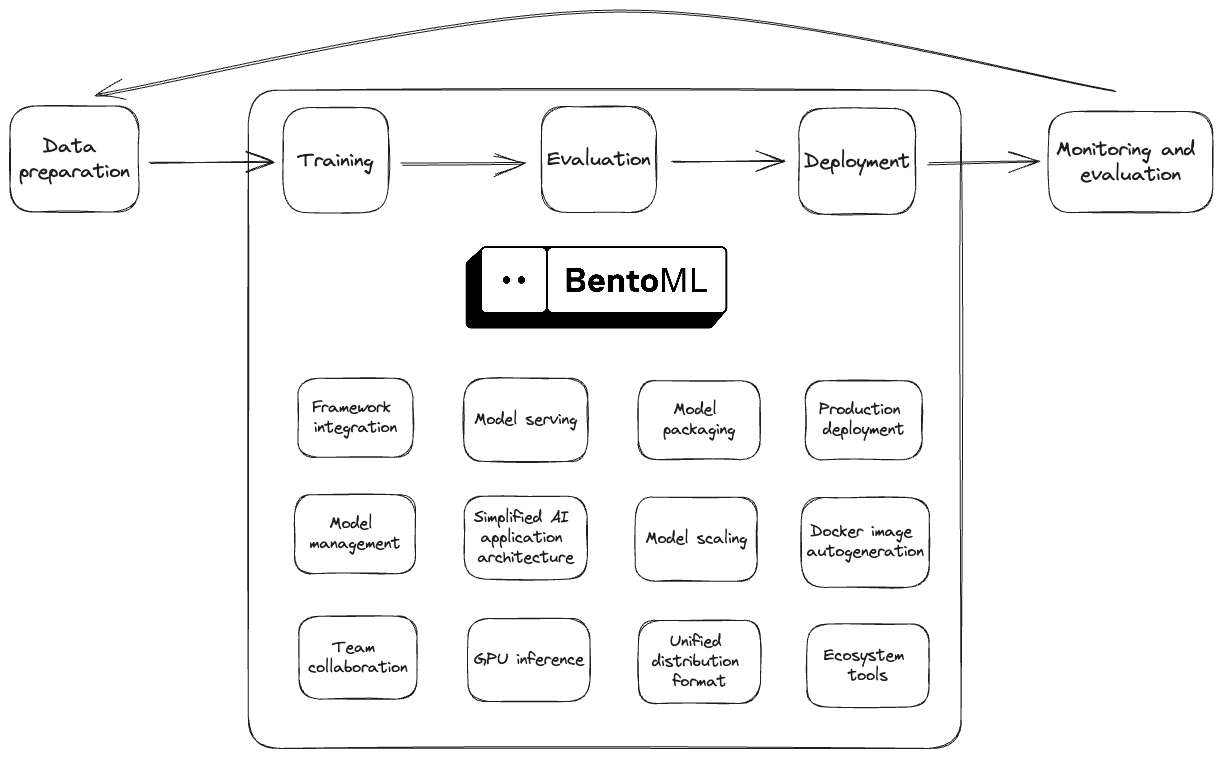
Specifically, here is how you use the BentoML framework.
Define a model#
Before you use BentoML, you need to prepare an ML model, or a set of models. These models can be trained using various libraries such as TensorFlow or PyTorch.
Save a model#
Register your model in the BentoML local Model Store with a simple Python function (for example, bentoml.diffusers.import_model()).
The Model Store serves as a management hub for all your models, providing easy access for serving as well as a systematic way to keep track of them.
As you evaluate trained models and iterate them, you can manage different model versions in the Store.
Create a Service#
Create a service.py file to wrap your model and lay out the serving logic. It specifies the Runners, an abstraction in BentoML designed to
optimize inference, and configures the external endpoint for interactions with users. You can use the Service to test model serving and get
predictions through HTTP or gRPC requests.
Build a Bento#
Package your model and the BentoML Service into a Bento through a configuration YAML file, which contains all the build options, such as Service, description, Python packages, models, and Docker settings. All created Bentos are stored in BentoML’s local Bento Store for centralized management. Each Bento corresponds to a directory that contains all the source code, dependencies, and model files required to serve the Bento, and an auto-generated Dockerfile for containerization.
Deploy a Bento#
To deploy a Bento to production, you can choose either of the following ways:
Containerize the Bento with the Dockerfile and deploy it to any Docker-compatible environments like Kubernetes.
Push the Bento to BentoCloud to manage your model deployments at scale. BentoCloud provides a serverless and scalable solution that allows you to run your AI applications on the best hardware per usage.