Adaptive batching#
Batching refers to the practice of grouping multiple inputs into a single batch for processing, significantly enhancing efficiency and throughput compared to handling inputs individually. In the context of machine learning and data processing, effective batching can dramatically improve performance, especially when dealing with high-volume or real-time data.
There are two main concepts in batching:
Batch window: The maximum duration a service waits to accumulate inputs into a batch for processing. This is essentially the maximum latency for processing in a low throughput system. It ensures timely processing, especially in low-traffic conditions, by preventing long waits for small batch completion.
Batch size: The maximum number of inputs a batch can contain before it’s processed. It it used to maximize throughput by leveraging the full capacity of the system’s resources within the constraint of the batch window.
BentoML provides a dispatching mechanism called “adaptive batching” that adapts both the batching window and the batch size based on incoming traffic patterns. The dispatching mechanism regresses the recent processing time, wait time, and batch sizes to minimize latency and optimize resource use.
This document explains the concept of adaptive batching in BentoML and its configuration.
Architecture#
In BentoML, adaptive batching is implemented on the server side. This is advantageous as opposed to client-side batching because it simplifies the client’s logic and it is often times more efficient due to traffic volume.
Specifically, there is a dispatcher within a BentoML Service that oversees collecting requests into a batch until the conditions of the batch window or batch size are met, at which point the batch is sent to the model for inference.
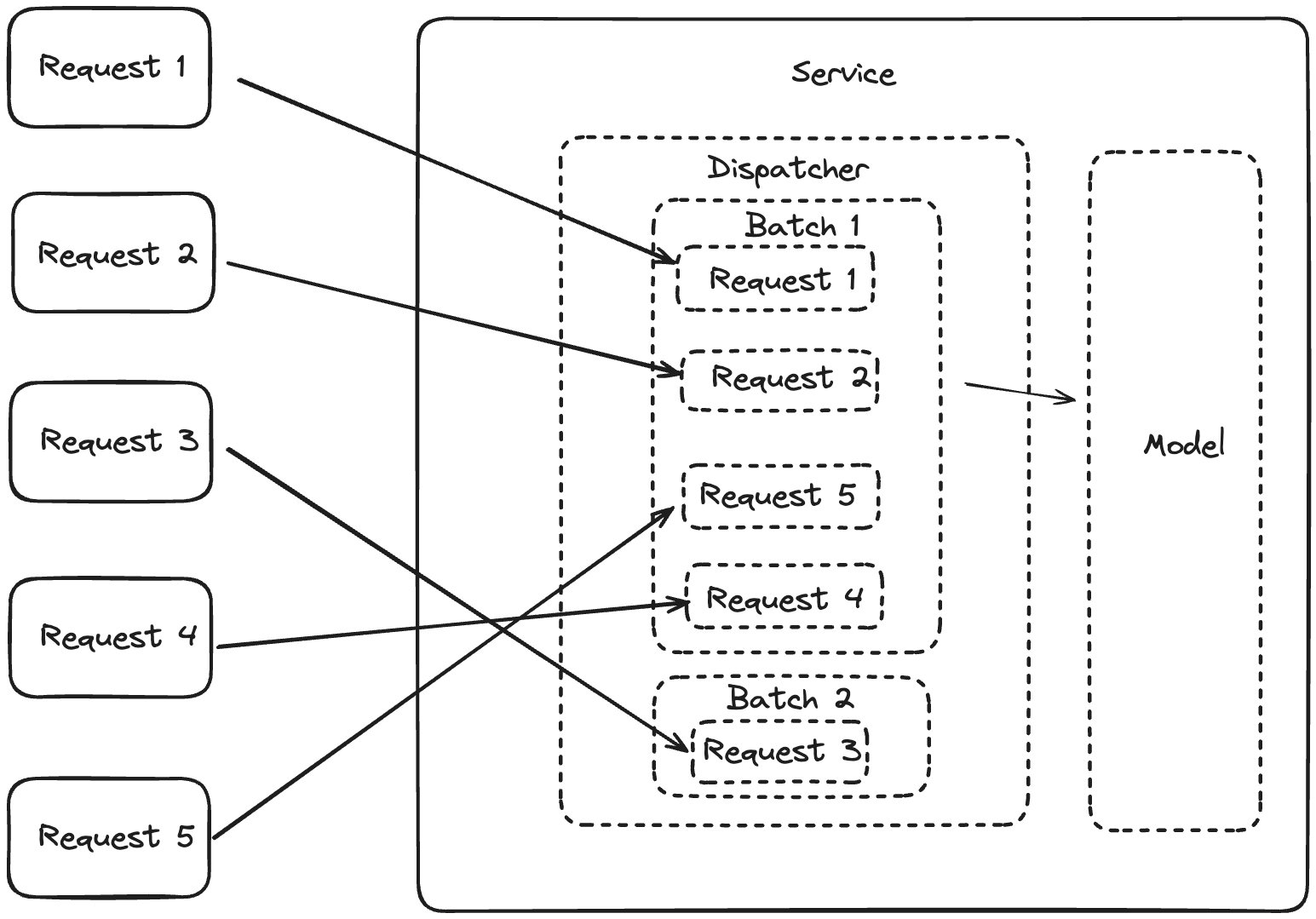
In scenarios with multiple Services, BentoML manages the complexity of batching across these Services. The Service responsible for running model inference (ServiceTwo in the diagram below) collects requests from the dependent Service (ServiceOne) and forms batches based on optimal latency.
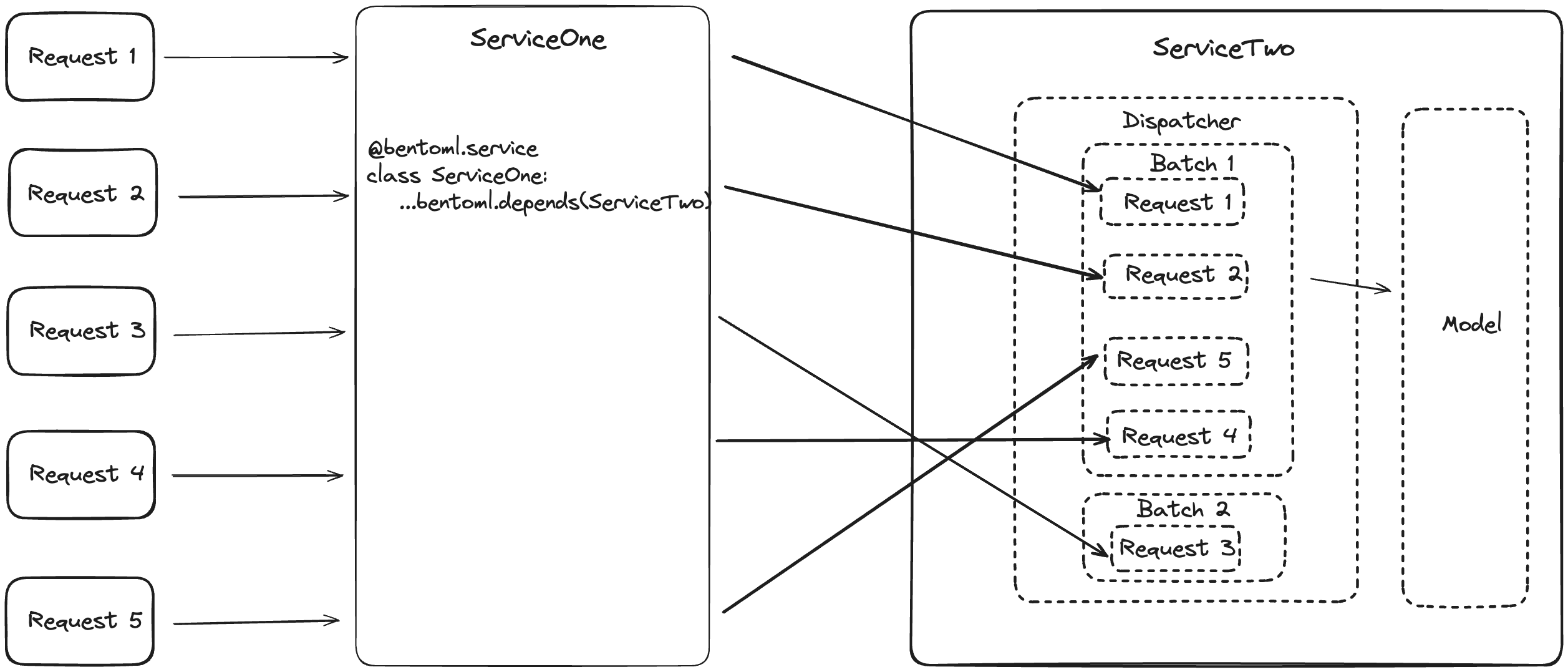
It is important to note that:
The adaptive batching algorithm continuously learns and adjusts the batching parameters based on recent trends in request patterns and processing time. This means that during high traffic time, batches are likely to be larger and processed more frequently, whereas during quieter periods, BentoML will prioritize reducing latency, even if that means smaller batch sizes.
You use the
bentoml.depends()function by passing the dependent Service class as an argument. This allows one Service to use the functionalities of another. This is particularly useful when the processing pipeline involves multiple steps or when different models are used in conjunction. For details, see Distributed Services.The order of the requests in a batch is not guaranteed.
Configure adaptive batching#
By default, adaptive batching is disabled. To enable and control it, you use the @bentoml.api decorator for your Service endpoint function, where you can specify various parameters to fine-tune how the batching behaves. Here’s an example of configuring adaptive batching for a Service.
import typing as t
import numpy as np
@bentoml.service(
resources={"gpu": 1, "memory": "8Gi"},
)
class BatchService:
def __init__(self):
# Model initialization and other setup code
@bentoml.api(
batchable=True,
batch_dim=(0, 0),
max_batch_size=32,
max_latency_ms=1000
)
# Use a list to handle multiple sentences in one batch
def encode(self, sentences: t.List[str]) -> np.ndarray:
# Logic to encode a list of sentences
@bentoml.api(
batchable=True,
batch_dim=(0, 0),
max_batch_size=32,
max_latency_ms=1000
)
# Use a np.ndarray to encapsulate multiple text inputs in one batch
def analyze_sentiment(self, texts: np.ndarray) -> t.List[str]:
# Logic to analyze sentiment for a batch of text inputs
Available parameters for adaptive batching:
batchable: Set toTrueto indicate that the endpoint can process requests in batches. When it is enabled, the batchable API endpoint accepts only one parameter in addition tobentoml.Context. This parameter represents the aggregated result of batching and should be of a type that can encapsulate multiple individual requests, such ast.List[str]ornp.ndarrayin the above code snippet.batch_dim: The batch dimension for both input and output, which can be a tuple or a single value.For a tuple (
input_dim,output_dim):input_dim: Determines along which dimension the input arrays should be batched (or stacked) together before sending them for processing. For example, if you are working with 2-D arrays andinput_dimis set to 0, BentoML will stack the arrays along the first dimension. This means if you have two 2-D input arrays with dimensions 5x2 and 10x2, specifying aninput_dimof 0 would combine these into a single 15x2 array for processing.output_dim: After the inference is done, the output array needs to be split back into the original batch sizes. Theoutput_dimindicates along which dimension the output array should be split. In the example above, if the inference process returns a 15x2 array andoutput_dimis set to 0, BentoML will split this array back into the original sizes of 5x2 and 10x2, based on the recorded boundaries of the input batch. This ensures that each requester receives the correct portion of the output corresponding to their input.
If you specify a single value for
batch_dim, this value will apply to bothinput_dimandoutput_dim. In other words, the same dimension is used for both batching inputs and splitting outputs.
Image illustration of
batch_dimThis image illustrates the concept of
batch_dimin the context of processing 2-D arrays.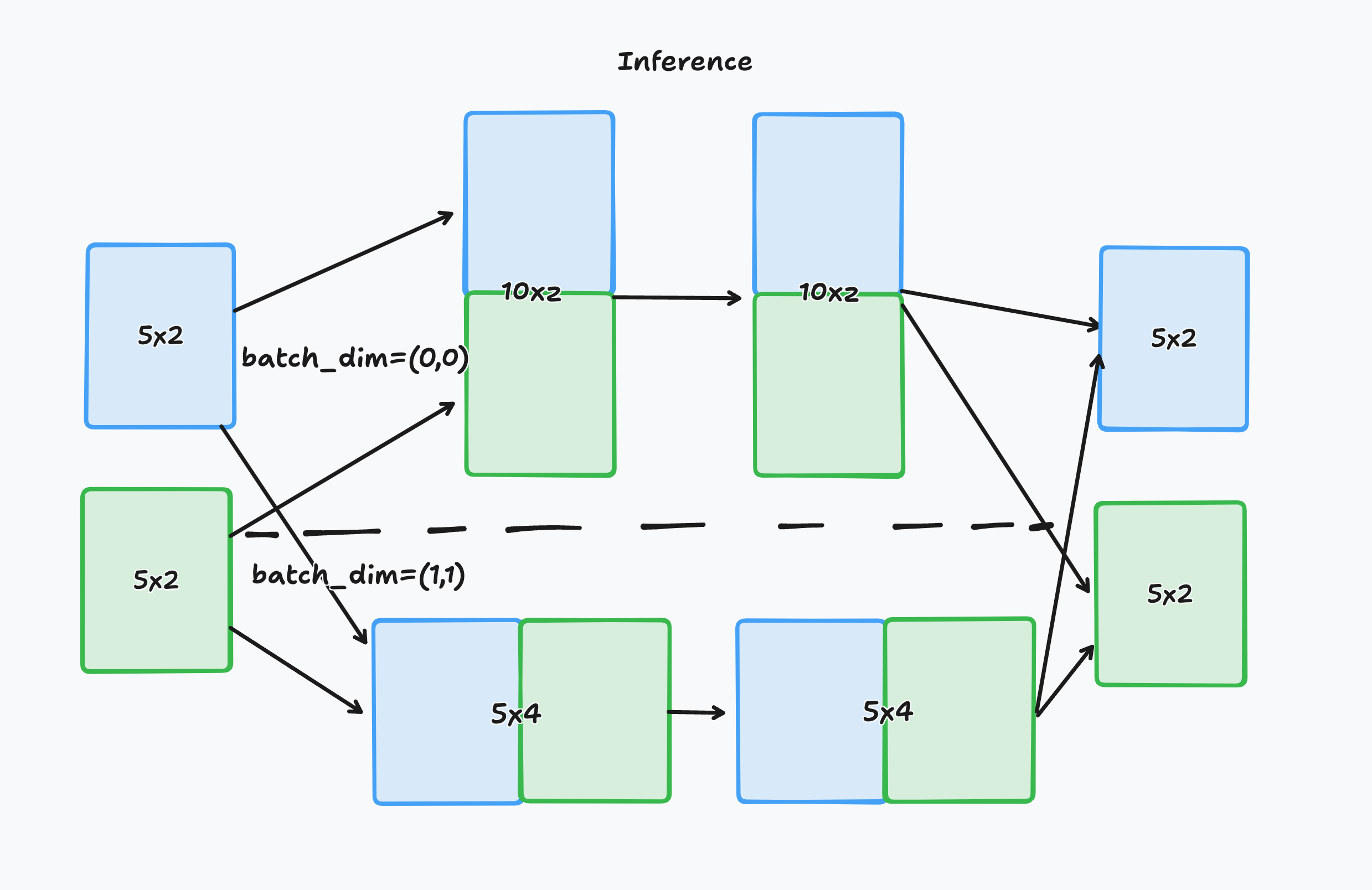
On the left side, there are two 2-D arrays of size 5x2, represented by blue and green boxes. The arrows show two different paths that these arrays can take depending on the
batch_dimconfiguration:The top path has
batch_dim=(0,0). This means that batching occurs along the first dimension (the number of rows). The two arrays are stacked on top of each other, resulting in a new combined array of size 10x2, which is sent for inference. After inference, the result is split back into two separate 5x2 arrays.The bottom path has
batch_dim=(1,1). This implies that batching occurs along the second dimension (the number of columns). The two arrays are concatenated side by side, forming a larger array of size 5x4, which is processed by the model. After inference, the output array is split back into the original dimensions, resulting in two separate 5x2 arrays.
max_batch_size: The upper limit for the number of requests that can be grouped into a single batch. It’s crucial to set this parameter based on the available system resources, like memory or GPU, to avoid overloading the system.max_latency_ms: The maximum time in milliseconds that a batch will wait to accumulate more requests before processing. Setting the maximum latency is essential to balance between throughput and the latency requirements of your Service.
Note
When you specify max_batch_size and max_latency_ms parameters, BentoML ensures that these constraints are respected, even as it dynamically adjusts batch sizes and processing intervals based on the adaptive batching algorithm. The algorithm’s primary goal is to optimize both throughput (by batching requests together) and latency (by ensuring requests are processed within an acceptable time frame). However, it operates within the bounds set by these parameters.
Below is a practical example of a Service that uses adaptive batching to encode sentences. It uses the SentenceTransformer model to generate sentence embeddings. With adaptive batching, it processes a list of sentences more efficiently.
from __future__ import annotations
import typing as t
import numpy as np
import torch
import bentoml
from sentence_transformers import SentenceTransformer, models
SAMPLE_SENTENCES = [
"The sun dips below the horizon, painting the sky orange.",
"A gentle breeze whispers through the autumn leaves.",
"The moon casts a silver glow on the tranquil lake.",
# ... more sentences
]
MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
@bentoml.service(
traffic={"timeout": 60},
resources={"memory": "2Gi"},
)
class SentenceEmbedding:
def __init__(self) -> None:
self.device = "cuda" if torch.cuda.is_available() else "cpu"
first_layer = SentenceTransformer(MODEL_ID)
pooling_model = models.Pooling(first_layer.get_sentence_embedding_dimension())
self.model = SentenceTransformer(modules=[first_layer, pooling_model])
print("Model loaded", "device:", self.device)
@bentoml.api(batchable=True, max_batch_size=32, max_latency_ms=1000)
def encode(
self,
sentences: t.List[str] = SAMPLE_SENTENCES,
) -> np.ndarray:
print("encoding sentences:", len(sentences))
sentence_embeddings= self.model.encode(sentences)
return sentence_embeddings
In this Service, the encode endpoint is marked as batchable. It’s configured to process up to 32 sentences at once and will wait no longer than 1 second to form a batch. This means if fewer than 32 sentences are received, the Service will wait for additional sentences to arrive within the 1-second window before proceeding with encoding.
Handle multiple parameters#
In some cases, you might need to use a BentoML Service to process requests that include multiple parameters. Since the batchable API supports only one batchable parameter (in addition to bentoml.Context), you can use a composite input type, such as a Pydantic model, to group these parameters into a single object. You also need a wrapper Service to serve as an intermediary to handle individual requests from clients.
Here is a service.py file example of defining multiple parameters when using adaptive batching.
from __future__ import annotations
from pathlib import Path
import bentoml
from pydantic import BaseModel
class BatchInput(BaseModel):
image: Path
threshold: float
@bentoml.service
class ImageService:
@bentoml.api(batchable=True)
def predict(self, inputs: list[BatchInput]) -> list[Path]:
# Inference logic here using the image and threshold from each input
# For demonstration, return the image paths directly
return [input.image for input in inputs]
@bentoml.service
class MyService:
batch = bentoml.depends(ImageService)
@bentoml.api
def generate(self, image: Path, threshold: float) -> Path:
result = self.batch.predict([BatchInput(image=image, threshold=threshold)])
return result[0]
Specifically, perform the following three steps to create a similar service.py file.
Define composite input types with Pydantic. The Pydantic model (
BatchInputin this example) groups together all the parameters needed for processing a batch of requests. EachBatchInputinstance represents a single request’s parameters, likeimageandthreshold.Create the primary Service for inference. The primary BentoML Service
ImageServicehas a batchable API method to accept a list ofBatchInputobjects. In this example, the method processes each input in the batch using the provided image and threshold values and returns a list of results.Set a wrapper Service for single requests. The wrapper Service defines an API
generatethat accepts individual parameters (imageandthreshold) for a single request. It usesbentoml.dependsto invoke theImageService’s batchablepredictmethod with a list containing a singleBatchInputinstance. The result for this individual request is then returned. For more information about creating multiple Services, see Distributed Services.
The primary Service performs the core inference logic in batches, improving efficiency and throughput. The wrapper Service serves as an interface for clients to send individual requests, encapsulating the complexity of batching and simplifying client interactions. This pattern enables you to leverage BentoML’s adaptive batching features while accommodating more complex input structures that include multiple parameters per request.
Error handling#
When a Service with adaptive batching enabled can’t process requests quickly enough to meet the maximum latency settings, it results in an HTTP 503 Service Unavailable error. To solve this, you can either increase the max_latency_ms to allow more time for batch processing or improve your system’s resources, such as adding more memory or CPUs.