Workers#
BentoML workers enhance the parallel processing capabilities of machine learning models. Under the hood, there are one or multiple workers within a BentoML Service. They are the processes that actually run the code logic within the Service. This design leverages the parallelism of the underlying hardware, whether it’s multi-core CPUs or multi-device GPUs.
This document explains how to configure and allocate workers for different use cases.
Configure workers#
When you define a BentoML Service, use the workers parameter to set the number of workers. For example, setting workers=4 launches four worker instances of the Service, each running in its process. Each worker is homogeneous, which means they perform the same tasks.
@bentoml.service(
workers=4,
)
class MyService:
# Service implementation
The number of workers isn’t necessarily equivalent to the number of concurrent requests a BentoML Service can serve in parallel. With optimizations like adaptable batching and continuous batching, each worker can potentially handle many requests simultaneously to enhance the throughput of your Service. To specify the ideal number of concurrent requests for a Service (namely, all workers within the Service), you can configure concurrency.
Use cases#
Workers allow a BentoML Service to effectively utilize underlying hardware accelerators, like CPUs and GPUs, ensuring optimal performance and resource utilization.
The default worker count in BentoML is set to 1. However, depending on your computational workload and hardware configuration, you might need to adjust this number.
CPU workloads#
Python processes are subject to the Global Interpreter Lock (GIL), a mechanism that prevents multiple native threads from executing Python code at once. This means in a multi-threaded Python program, even if it runs on a multi-core processor, only one thread can execute Python code at a time. This limits the performance of CPU-bound Python programs, making them unable to fully utilize the computational power of multi-core CPUs through multi-threading.
To avoid this and fully leverage multi-core CPUs, you can start multiple workers. However, be mindful of the memory implications, as each worker will load a copy of the model into memory. Ensure that your machine’s memory can support the cumulative memory requirements of all workers.
You can set the number of worker processes based on the available CPU cores by setting workers to cpu_count.
@bentoml.service(workers="cpu_count")
class MyService:
# Service implementation
GPU workloads#
In scenarios with multi-device GPUs, allocating specific GPUs to different workers allows each worker to process tasks independently. This can maximize parallel processing, increase throughput, and reduce overall inference time.
You use worker_index to represent a worker instance, which is a unique identifier for each worker process within a BentoML Service, starting from 0. This index is used primarily to allocate GPUs among multiple workers. One common use case is to load one model per CUDA device to ensure that each GPU is utilized efficiently and to prevent resource contention between models.
Here is an example:
import bentoml
@bentoml.service(
resources={"gpu": 2},
workers=2
)
class MyService:
def __init__(self):
import torch
cuda = torch.device(f"cuda:{bentoml.server_context.worker_index-1}")
model = models.resnet18(pretrained=True)
model.to(cuda)
This Service dynamically determines the GPU device to use for the model by creating a torch.device object. The device ID is set by bentoml.server_context.worker_index - 1 to allocate a specific GPU to each worker process. Worker 1 (worker_index = 1) uses GPU 0 and worker 2 (worker_index = 2) uses GPU 1. See the figure below for details.
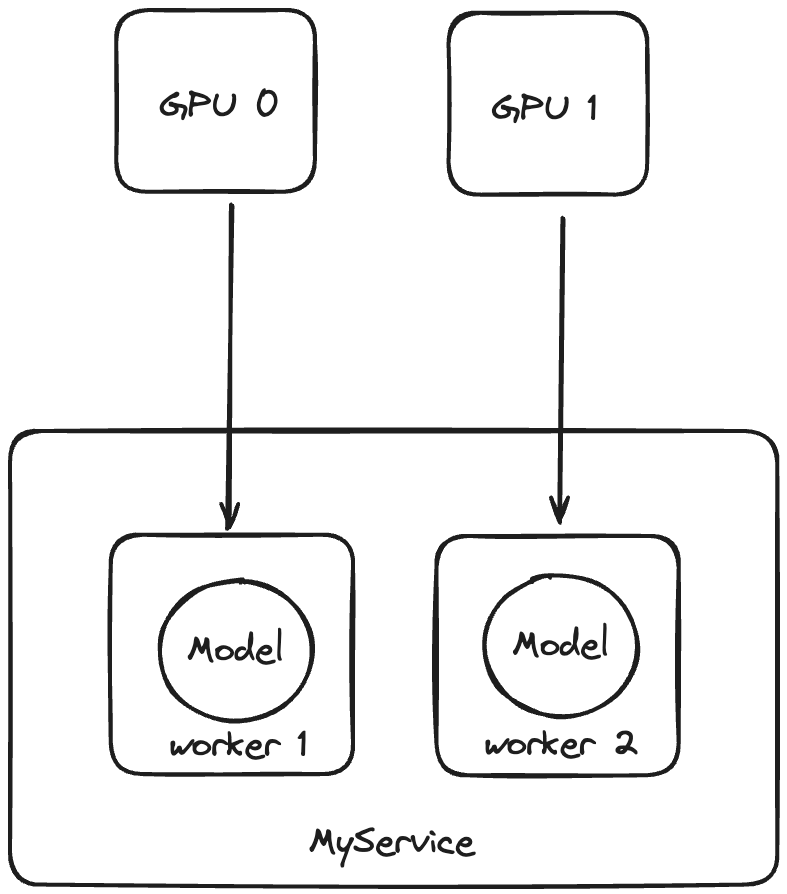
When determining which device ID to assign to each worker for tasks such as loading models onto GPUs, this 1-indexing approach means you need to subtract 1 from the worker_index to get the 0-based device ID. This is because hardware devices like GPUs are usually indexed starting from 0. For more information, see GPU inference.
If you want to use multiple GPUs for distributed operations (multiple GPUs for the same worker), PyTorch and TensorFlow offer different methods:
PyTorch: DataParallel and DistributedDataParallel
TensorFlow: Distributed training